
According to the IPCC, economic growth and increasing human populations are the two main drivers of global climate disruption. However, to date only efficiency improvements and technological changes have been seriously considered to meet the goals of the UNFCC’s Paris Agreement. In a new study, we examine how the parties to the agreement dealt with population growth in their Nationally Determined Contributions (NDCs), the national action plans submitted to the UN under the treaty. Only 7 of 164 national plans included strategies to slow population growth, and none specified detailed implementation measures. Revised plans are now being written and submitted, and we encourage national policymakers to plan and implement actions to reduce population growth, such as fully funding family planning programs and providing universal access to modern contraceptives to all their citizens.
by The Overpopulation Project
The Paris Agreement in 2015 was considered a success at the time, given earlier difficulties in reaching any international climate treaty at all. Since then, many analysts have emphasized that the agreement is voluntary, and thereby limited and uncertain in what individual nations will actually achieve. The mitigation aim of the agreement is to “set the world on a course towards sustainable development, aiming at limiting warming to 1.5 to 2 degrees C above pre-industrial levels”. The parties also agreed to a “long-term goal for adaptation – to increase the ability to adapt to the adverse impacts of climate change and foster climate resilience … in a manner that does not threaten food production”. The Paris Agreement required that the signatory parties send in plans, so called Nationally Determined Contributions (NDCs), to help fulfill the goals of the treaty. National commitments to date under the NDCs would not be sufficient to achieve the treaty’s mitigation or adaptation goals, even if all the voluntary steps they mention were taken.
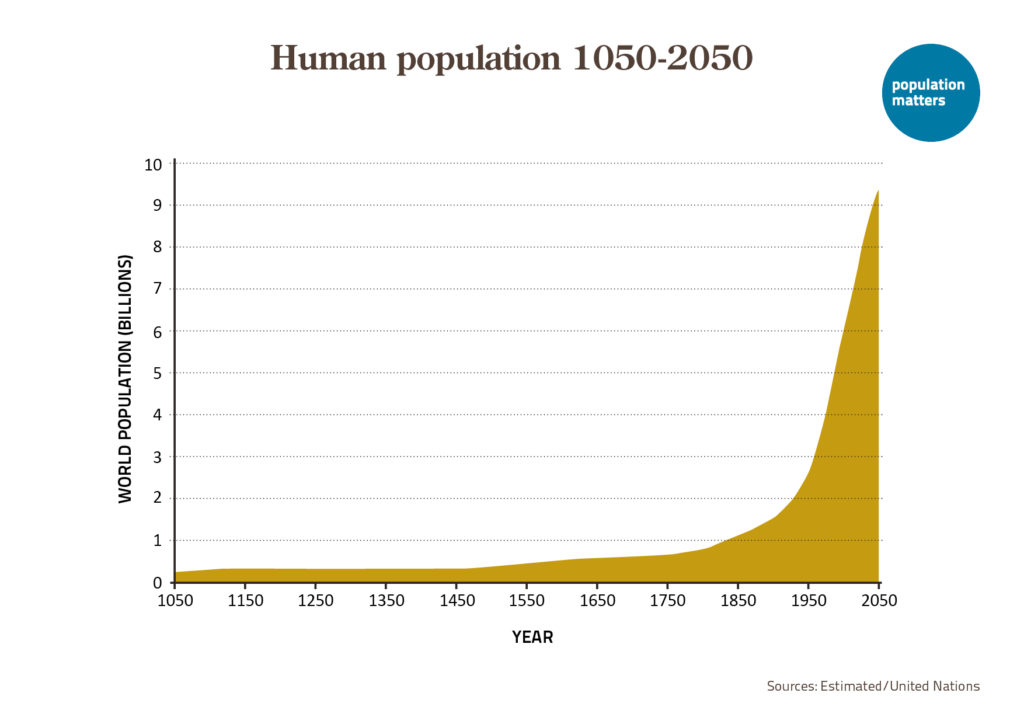
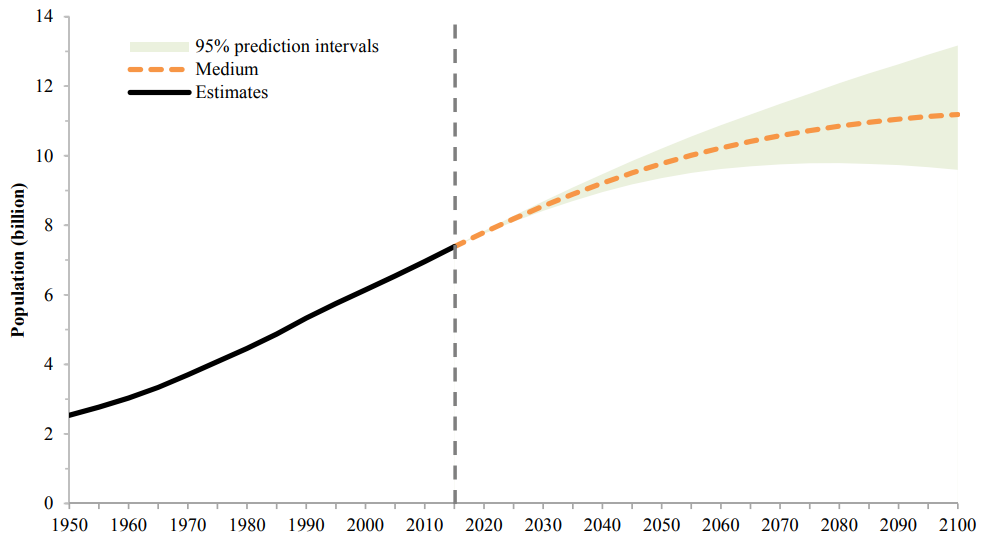
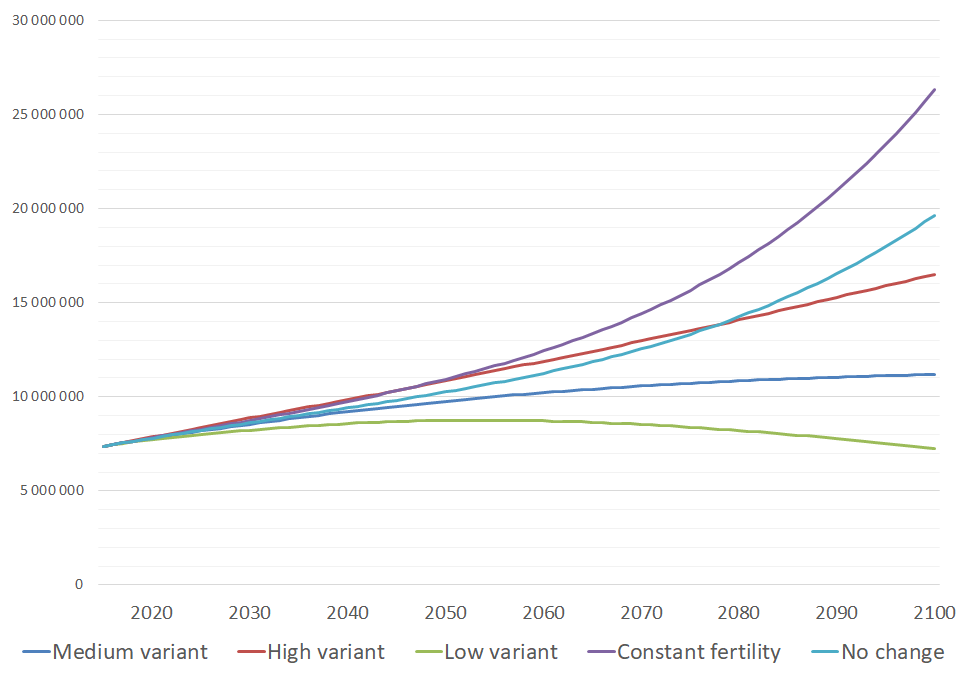
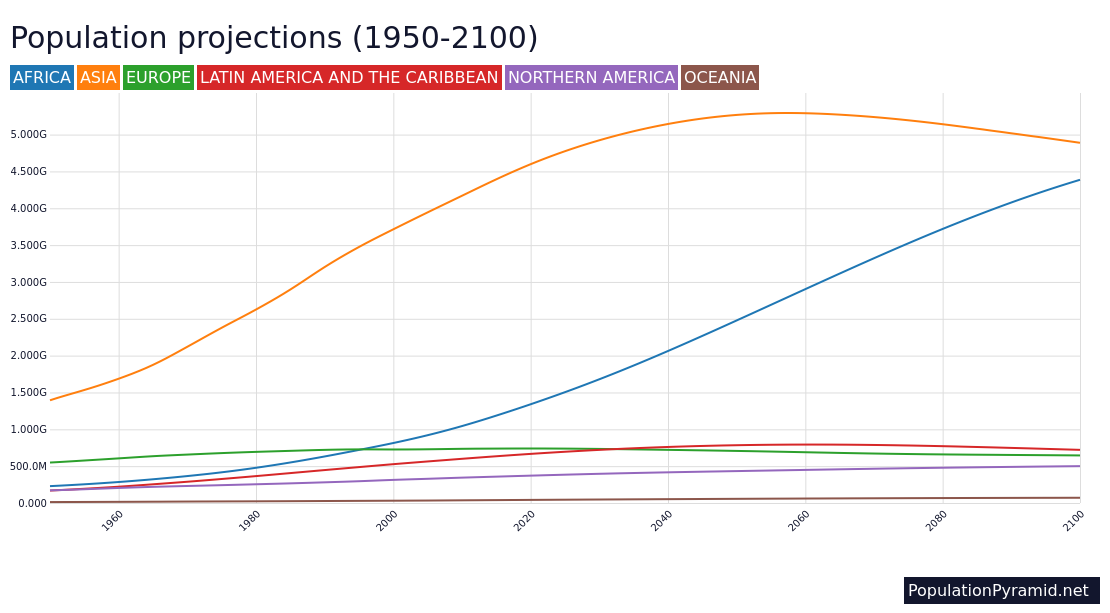
Population growth is a driver of both climate vulnerability and climate-altering emissions. In TOP’s new working paper, “Population Growth and Family Planning in the Nationally Determined Contributions (NDCs) made under the Paris Climate Agreement,” we ask to what extent countries take population growth into account. To do this, we made a comprehensive text review of the first round of 164 NDCs submitted under the Paris Agreement. We distinguished between simple statements of population trends, included in most submissions, and substantive discussions of population’s impacts on mitigation or adaption goals.
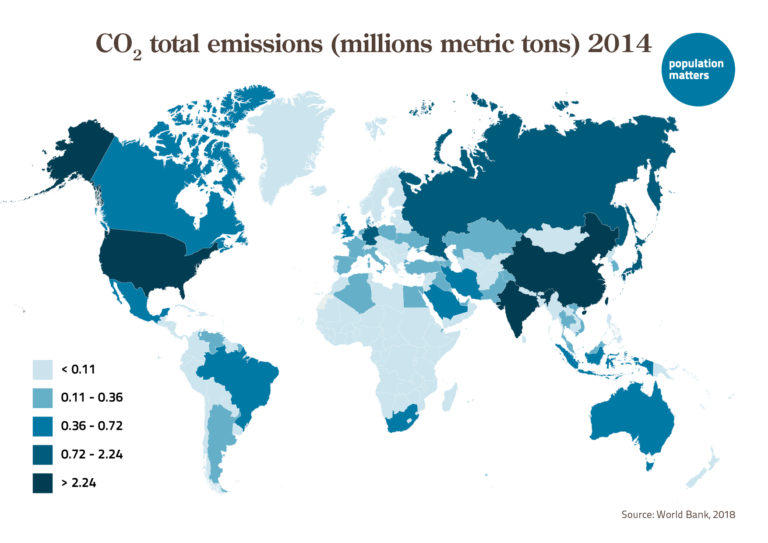
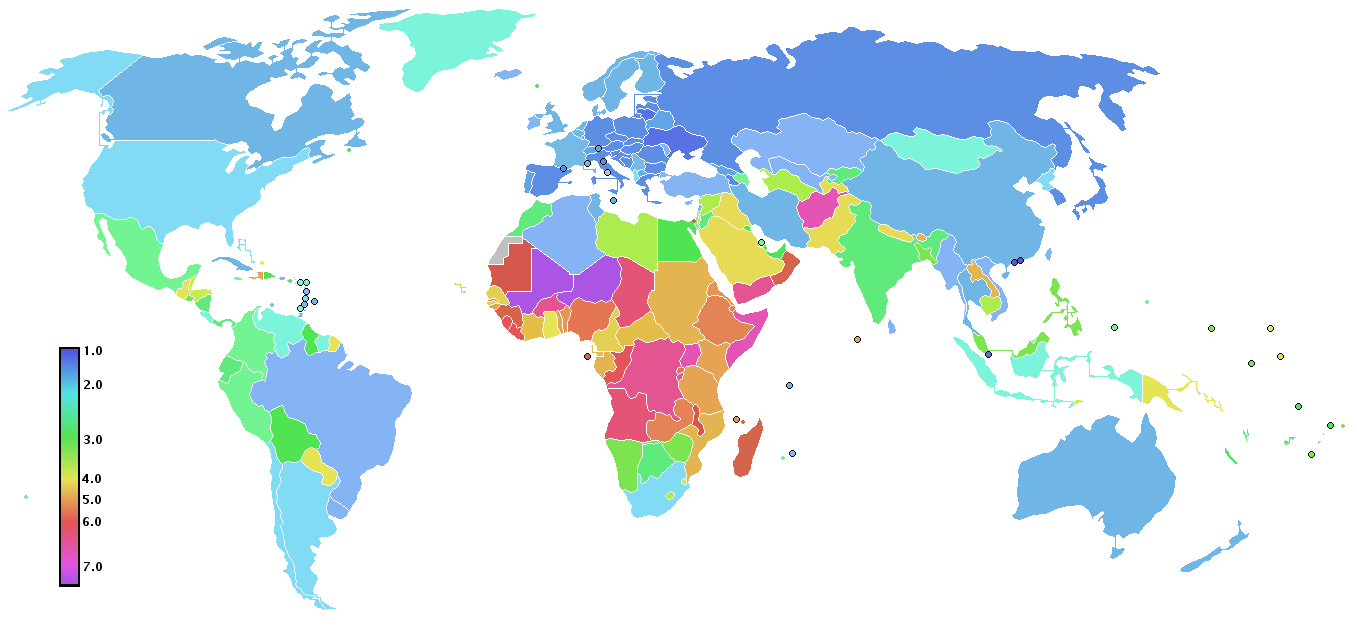
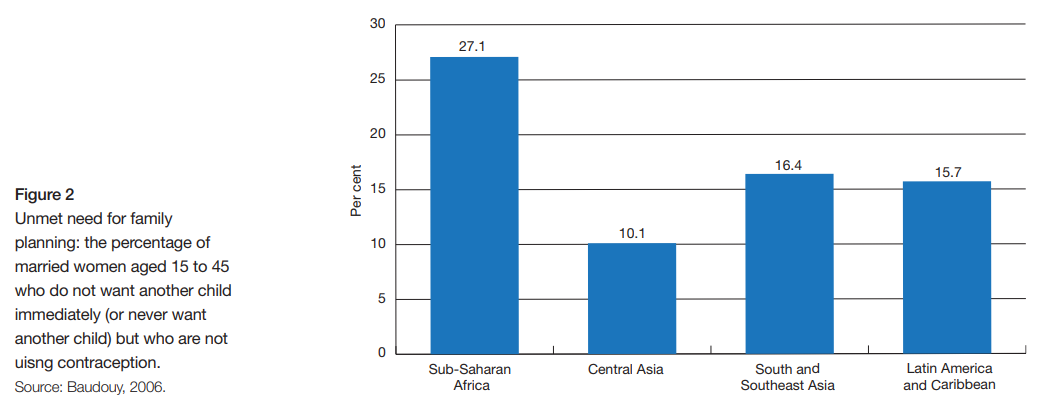
A number of countries included at least one impact of population growth in their NDC (’population inclusive’, see map below). About one-third (49) of the NDCs either link population growth to a negative effect and/or identify population growth as a challenge or trend affecting societal needs. As might be expected, these countries had a significantly higher population growth rate and unmet need for family planning than those with no substantive attention to population growth.

The impacts of population growth identified in the NDCs were increased energy demand, natural resource degradation, vulnerability to climate impacts, and decreased food and water security. These are all serious impacts that in turn could severely harm people and other species. Yet only 7 NDCs, from countries representing only 2 ½ % of the global population, included an action to slow population growth: Mali, Mauritius, Egypt, Togo, Niger, Uganda and Tunisia (see chart below). These actions were primarily adaptation measures, national development priorities, or means of NDC implementation. Only 2 of these 7 NDCs (Mauritius and Uganda) included clear strategies to slow population growth; the others described ambiguous efforts, or included a population goal but provided no implementation measures. No national NDC, some of which ran to hundreds of pages, described detailed implementation measures to reduce population growth.

Parties to the Paris Agreement are now working on a new round of revised NDCs. The secretariat for the UN’s climate agreement and its Climate Action Tracker reports that as of December 10, 2020, 19 countries had submitted new NDC targets, but only three (Chile, Norway, Vietnam) submitted overall stronger targets. In total 164 countries have not yet submitted a revised plan.
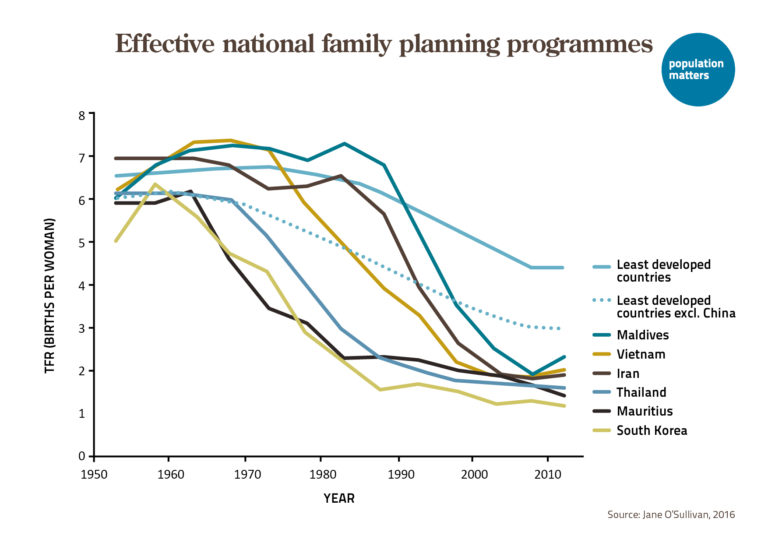
In the ongoing revision of the NDCs, all governments need to carefully consider the potential impact of population growth on mitigation and adaptation efforts. As TOP recently reported in our review paper “Population Growth and Climate Change: Addressing the Overlooked Threat Multiplier”, slowing growth and stabilizing population is especially important for climate adaptations, such as minimizing heat exposure in vulnerable regions. Moreover, governments need to prioritize meeting unmet needs for family planning, and integrate population-health-environment projects into their national climate plans. In addition, low-fertility countries with declining populations, such as Japan and several European countries, should emphasize this beneficial aspect (see TOPs earlier study about the advantages of aging and declining populations).
Read and spread the results of our working paper to media and politicians in your country! Comments and criticisms are welcome, too.












Leave a Reply